

Back in '48
Back in '48
Nunca tantos le debieron tanto a tan pocos, sobre todo si esos pocos son uno solo.

Number Six: Where am I?
Number Two: In the Village.
Number Six: What do you want?
Number Two: Information.
Number Six: Whose side are you on?
Number Two: That would be telling. We want information… information… information.
Number Six: You won't get it.
Number Two: By hook or by crook, we will.

¡Canta, Oh Musa!
No importa cuándo, en el 510 y en el 2000 también, tenemos la tendencia general de leer la historia como la historia de los grandes hombres (o mujeres, o sujetos de cualquier tipo, lo mismo da) que la hicieron: un buen día llegó Galileo y repensó la estructura del movimiento, volteando de paso la estantería aristotélico-tomista, vino Watt y sacó de la galera la máquina de vapor, Turing, solo y su alma, inventó las computadoras. Esta tendencia a entender la historia así se puede equiparar al Culto de los Heroes: la idea de que vivimos un mundo mas o menos llano, punteado aquí y allá por picos solitarios que se destacan en la niebla general. Esto se puede ver con optimismo o con pesimismo, dependiendo de quién sea uno y cuánto haya bebido. Pero la lectura heroica de la historia no se corresponde demasiado con la realidad. Digamos, para entender a Galileo, Watt o Turing uno tendría que entender, respectivamente, la concepción franciscana del mundo como el segundo libro de Dios, que debe ser leído con tanto cuidado como el primero, la maquina de Newcombe, o los esfuerzos separados pero simultáneos de Post, Markov, Church y varios otros. Pero también es posible irse demasiado para el otro lado: pensar en la historia, en este caso en la historia de la ciencia, como el resultado de la acción anónima e inevitable de la nube de midiclorias, o del Zeitgeist, según la mitología que esté de modas, donde el espíritu, tan platónico él, se mueve sobre las aguas y va usando como un titiritero a distintos sujetos, que son completamente inocentes de lo que resulta. No sé ustedes, yo creo ya es hora de decir: cortémosla con la pavada. La historia es una cosa concreta que pasó, y la manera de empezar a entenderla es mirar lo que efectivamente pasó. Gente real, haciendo cosas reales, influyendo, e influidos por, el quilombo general, bamboleándose como monos locos en la niebla. Y en estos días, leyendo una biografía1 de uno de los sujetos más interesantes que ocurrieron en este planeta desde que nos bajamos de los árboles, volví a saber que muy poca gente sabe quién es, aunque vivan en un mundo hecho, en gran medida, por sus ideas. Estoy hablando de Claude Shannon, uno de los tipos más influyentes, y menos conocidos por el gran público, del siglo XX. Y de su hija dilecta (aunque tuvo otras), la Teoría de la Información. Aunque no la inventó solo, es probablemente lo más cerca que alguien haya estado de cambiar el mundo a puro genio.
Comunicado número 1
En 1948, después de un doctorado en MIT y un tiempito en el Instituto de Estudios Avanzados en Princeton, Claude Shannon trabajaba en Bell Labs, los laboratorios de investigación de la empresa AT&T, uno de los lugares en los que se invento la revolución tecnológica del siglo XX. Para que se den una idea, Bell Labs ganó 10 premios Nobel en ciencias: si fuera un país, compartiría el décimo segundo lugar en el ranking con Dinamarca. Entre sus logros están la invención de la radioastronomía, los transistores, Unix, la primera descripción de los laser, y la primera medición de la radiación cósmica de fondo, que termino de demostrar la existencia del Big Bang. Trabajando en problemas relacionados con como mejorar las telecomunicaciones, Shannon empezó a tratar de definir qué es la información que se comunica, y cómo medirla, y publicó sus ideas en un famoso paper, The Mathematical Theory of Communication. La idea de Shannon fue intentar definir la información dejando de lado toda consideración psicológica o perceptual, enfocarse en un proceso de transmisión, no en cómo interpretar el significado de lo que se transmite. El proceso que analizó está en la siguiente figura.
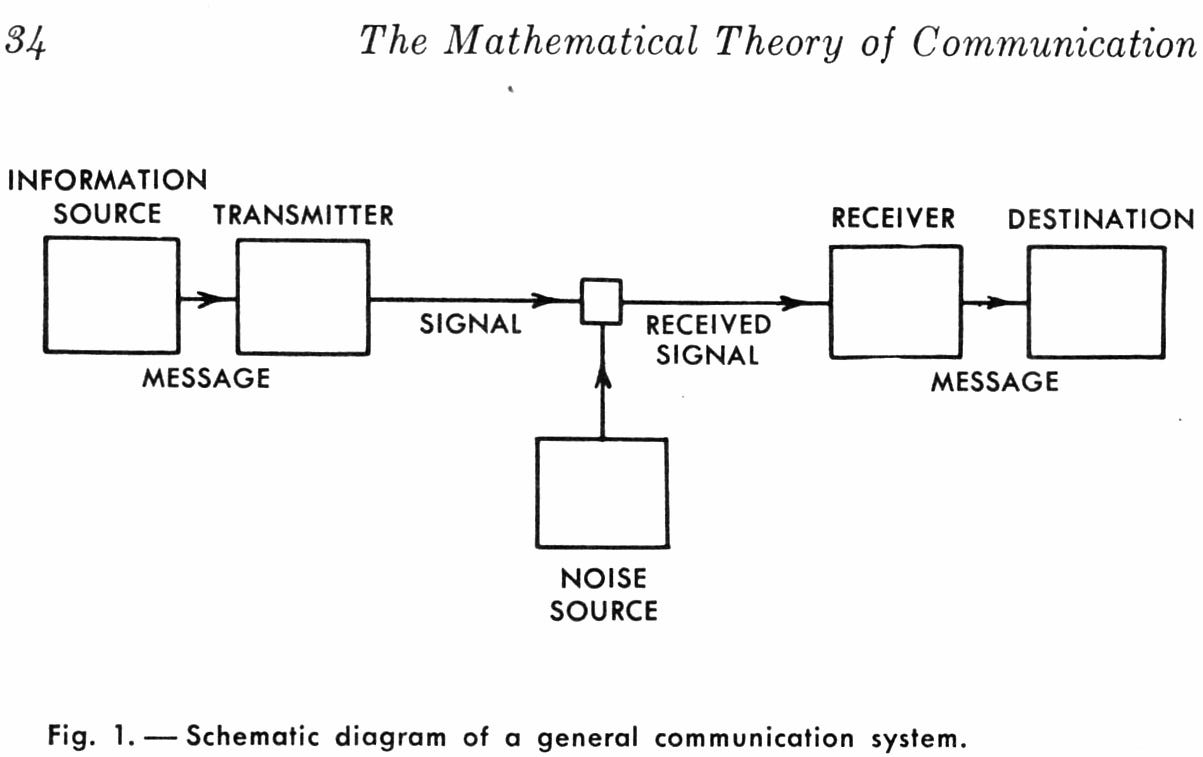
La fuente envía un mensaje al transmisor, que lo transmite mediante una señal, que es recibida por un receptor, que reconstruye el mensaje para el destinatario. El objetivo es que el mensaje enviado y el recibido sean idénticos. Y como la vida no es fácil, en el camino el mensaje esta contaminado de ruido (y llamamos ruido a cualquier cosa cambie o altere el mensaje transmitido). Lo bueno de modelarlo así es que podemos enfocarnos en un problema por vez: primero canales sin ruido, y después le agregamos la complicación adicional. Bien de ingeniero.
A partir de esto, Shannon construyo casi todo el campo de la teoría de la información. Vamos a ver como, si ENTEL no nos corta el canal.
Odol Pregunta
Claro que todavía no definimos qué es información. Si tuviéramos una biblioteca que contuviera 1000 millones de copias idénticas de Hamlet, ¿tendría mas informacion que otra con solo dos libros, Hamlet y el Análisis I de Piskunov? Intuitivamente, no. Todo lo que se puede leer en la biblioteca uno se puede leer también en la biblioteca dos, pero no viceversa. Aunque la biblioteca uno sea mas grande, en el sentido de espacio ocupado, no tiene más información. Pero como la intuición suelta es más peligrosa que mono (loco) con navaja, vamos a tratar de darle forma a esto
Imaginemos un pseudo-dado de cuatro caras, A, B, C y D, que tienen todas las misma probabilidad de salir, y usémoslo para jugar un juego: un jugador tira el dado, y tapa el resultado con la mano. El otro hace preguntas hasta que adivina qué valor salió. Juegan 100 veces, y gana el que hace menos preguntas en total. Nadie hace trampa porque usamos personas esféricas y sin rozamiento para el experimento.
La primera idea que se nos ocurre es la siguiente: Preguntamos si es A. Si no, preguntamos si es B. Si no, preguntamos si es C, si no, ya sabemos que es D. Podemos verlo en el siguiente esquema.
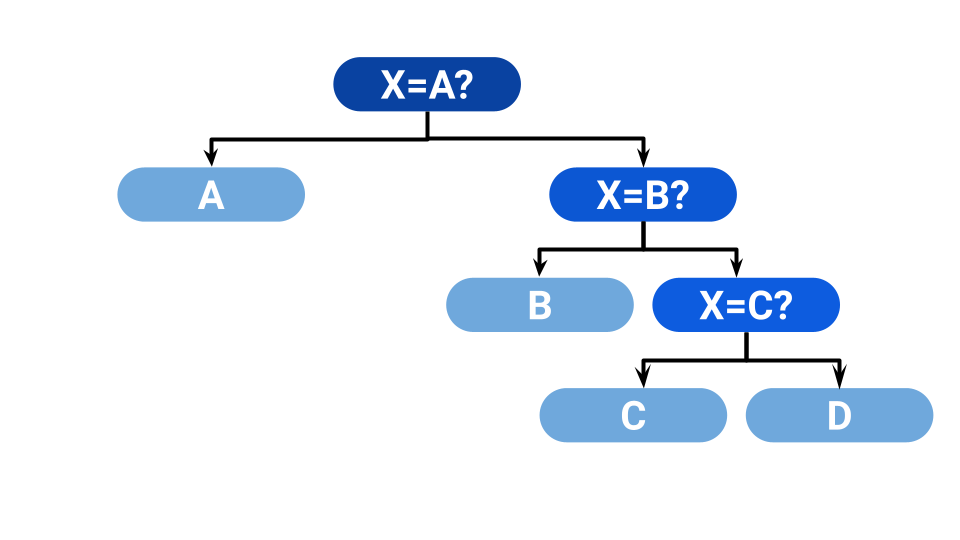
¿Cuántas preguntas tenemos que hacer? Si salió A, 1 pregunta, si salió B, 2, si salieron C o D, 3. Si seguimos jugando un rato largo, como cada signo tiene un 25% de chance de salir, haremos en promedio 25% × 1 + 25% × 2 + 50% × 3 preguntas. O sea, 2.25 preguntas por juego, en promedio. ¿Es lo mejor que podemos hacer? Resulta que no. Podemos reorganizar nuestras preguntas como sigue:
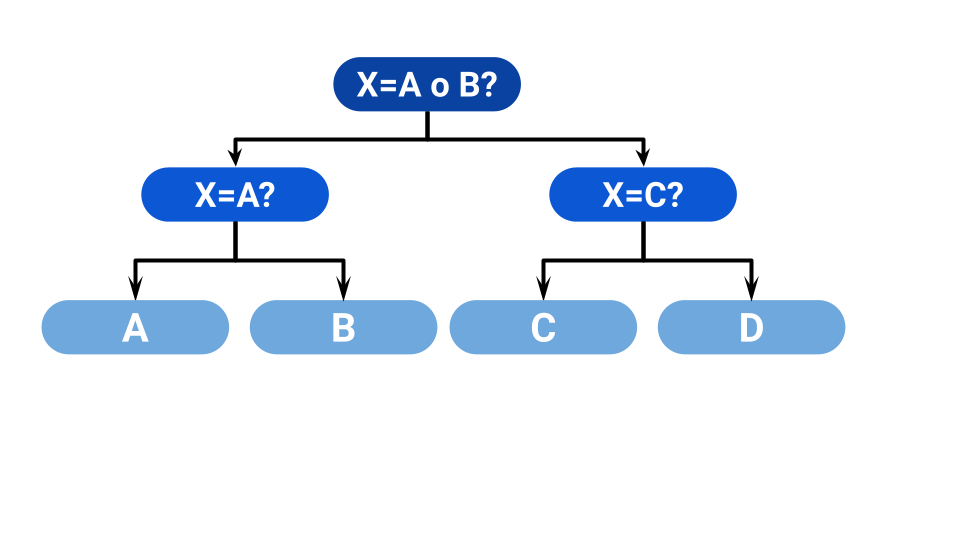
Si lo hacemos así resulta que en todos los casos hacemos 2 preguntas, con lo que el promedio nos da 2, en vez de 2.25. Lo interesante es que para cada juego (o sea, para cada dado con sus caras y probabilidades), hay una cantidad mínima de preguntas promedio que tenemos que hacer para saber qué salió. Esa cantidad, a la que Shannon la llamo Entropía, es la cantidad de Información promedio de nuestro sistema. Pero, ¿qué tiene que ver esto con las comunicaciones? Fíjense que las preguntas que hacemos definen un código binario, una secuencia única de unos y ceros, que representa los resultados. ¿Cómo? Piensen que juego el juego y, por vez que tomo para la izquierda en el diagrama, anoto un 1, y por cada vez que voy para la derecha, un 0, hasta llegar a la letra que busco. En el primer caso, el camino a la A es 1, el camino a la B es 01, el camino a la C es 001, el camino a la D es 000. En el segundo, A es 11, B es 10, C es 01, D es 00. Pero eso quiere decir que si la Información Promedio de un juego es igual al número de preguntas promedio que necesito para decidir que paso con el juego, y el número de preguntas es el número de bits que necesito para codificar el resultado, entonces la información promedió es el número de bits promedio que necesito para representar los mensajes de una fuente. O sea: a mayor información, mayor número de bits, a menor información, menor número de bits se necesitan para comunicar los resultados del juego. Si mi dado tiene una sola cara, y pase lo que pase siempre sale A ¿cuántos bits necesito para representarlo? Ninguno. Siempre sale lo mismo. El receptor sabe lo que dije porque solo puedo decir una sola cosa. Es como el guion de una película de Steven Seagal.
Si odian las formalizaciones, salteen este párrafo, o tomen un repelente de antiformalizaciones. Shannon define la información de un símbolo S cualquiera que una fuente F puede producir como
Donde pS es la probabilidad de que la fuente produzca S. Es largo explicar por qué, pero es la única función que cumple varias propiedades que nos gustan, en particular que crece cuanto menos probable es el símbolo, y que hace que la información sea aditiva (la información que obtenemos de dos símbolos terminan siendo la suma de la información de ambos símbolos). La entropía de F, el número de bits promedio que necesitamos para codificar las secuencias de símbolos que F produce, es
Shannon bautizó a la información promedio con el bonito nombre de entropía, según cuenta la leyenda, porque cuando le presentó la idea a John von Neumann, este le dijo que la ecuación era idéntica a la que se usa en termodinámica para la entropía, y agrego que si le ponía ese nombre nadie iba a discutírsela porque nadie entiende qué demonios es la entropía.
Ok. Ya pueden abrir los ojos. No hay más fórmulas de acá en adelante. Para decirlo de un modo menos formal, la información es una medida de la sorpresa que nos provoca ver un símbolo. ¿Cuándo es minima la entropía? o sea, ¿cuándo es mínima nuestra sorpresa al ver un símbolo? Obvio, cuando produce siempre un único símbolo y su probabilidad es 1 y la entropía es 0. Y ¿cuándo es máxima? Con un poco de ojo se ve que la fuente tiene máxima información cuando todos los símbolos tienen la misma probabilidad. Lo que, pensándolo bien, es obvio: Si hay algún símbolo que tenga mas chance que los demás, lo describo con menos bits (lo encuentro con un numero menor de preguntas) y reduzco la cantidad de preguntas necesarias en promedio (porque como es mas probable, voy a seguir ese camino mas corto mas veces). Si todos son igualmente probables, no tengo manera de hacer eso.
Hasta ahora pensamos en que la fuente envía símbolos en forma independiente, donde un simbolo no depende del anterior. Imaginate que nuestros símbolos son palabras del castellano, si dije “los”, que el proximo símbolo sea “caballos” es mucho mas probable que “yeguas”, por esas cositas de la coordinación de genero y numero. No es imposible, podríamos estar en un poema de Juan Gelman y ahi quién sabe, entonces las ecuaciones cambian un poco (no me voy a poner a escribirlas acá, pero dependen de la probabilidad no del signo sino de la secuencia de signos). Pero la teoría sigue funcionando.
Un paso mas (y todavía no estamos en orsai).
Estamos hablando de una teoría de la comunicación, asi que evidentemente en alguna parte tiene que entrar a tallar el hecho de transmitir datos. Y el resultado de Shannon se extiende hermosamente a lo siguiente: cada canal de transmisión de datos tiene una capacidad, a la que medimos en transmisión por unidad de tiempo (por ejemplo, en bits2/segundo, llamados baudios en sánscrito antiguo).
Ahora bien, la capacidad del canal es una capacidad física y, mientras no cambie la tecnología del canal, incambiable. ¿Cuál es la tasa máxima efectiva de transmisión de nuestro canal? Lo que Shannon probo es que la capacidad del canal dividida por la entropía de la fuente. O sea, lo que puedo transmitir por un canal no depende solo del tamaño de lo que quiero transmitir, sino también de cuan redundante es. O sea, podemos comprimir mensajes para que quepan mas. Pero hasta un límite.
Teorema para que el lector demuestre en casa: para transmitir el guión de una película de Steven Seagal, todo canal tiene capacidad infinita.
Errare binarium est
Ahora, algo no esta del todo bien. A las hermanastras de Cenicienta no les entraban los pues en el zapatito de cristal usurpado. Entonces, dado que esta no esta en la version de Disney sino la de Tarantino, procedieron a cortarse los dedos de los pies para ver si podían encajar la empanada en el calzado y alzarse con el principe casadero. En términos de información, si el canal no te alcanza para el mensaje, podes probar achicar el mensaje. Pero ya dijimos que no podes achicarlo mediante compresión (la redundancia, o sea la entropía, te da la maxima compresión posible). Achicar el mensaje mas allá de la entropía es posible solamente perdiendo señal, o dedos de los pies (si en vez de imaginarte ser la hermana psicotica de un personaje imaginario te imaginas ser un audiofilo, es lo que pasa cuando pasas de un CD -mas o menos 1 megabit por segundo- a MP3 -menos de 320 kilobits por segundo-. La compresion de MP3 es mayor que la que permite la entropia de la fuente, y por eso decimos que es lossy: pierde informacion y el receptor del otro lado del canal no va a poder reconstruir perfectamente la señal. Lo que Shannon demostró es que para cualquier nivel de pérdida que estés dispuesto a aceptar, hay un nivel de compresión adicional que podes ganar. Pero acá entra a tallar otra cosa que es equivalente a la pérdida, y que está en el esquema de Shannon, y que hasta ahora logramos dejara afuera de la charla, y es el ruido. ¿Qué es el ruido? Cualquier cosa que altere el mensaje transmitido: desde interferencia hasta errores de todo tipo, incluso si el operador del mecanismo se distrae leyendo las peripecias de Cenicienta y cada tanto manda un uno donde debería de ir un cero. Y lo que Shannon muestra es que en realidad el ruido es equivalente a la compresión excesiva: nos genera una señal que no se puede decodificar sin pérdida, pero entonces podemos resolverla agregando redundancia -alargando- el código, de modo que para cualquier nivel de ruido y cualquier nivel de pérdida de señal aceptable, es posible encontrar un código (a veces tan largo que no es práctico, pero que de todos modos existe) que nos permite transmitir nuestro mensaje en forma íntegra, y si tiene errores, detectaros o aun corregirlos. En el límite, nuestro ADN no sólo tiene dos copias de cada unidad de información (aunque en vez de expresarlas en términos de unos y ceros como una línea digital las expresa con cuatro distintos nucleótidos, (A, C, T y G), que van pareados de un modo particular (enfrente de cada A siempre hay un T, de cada T un A, y lo mismo pasa con C y G). O sea, extiende el código, duplicando su longitud, para poder garantizar muy pocos errores (también hace otras cosas, pero esto se está volviendo largo).
Al fin.

En un solo paper, Shannon definió toda una nueva rama de conocimiento, la teoría de la información, en un lugar donde ingeniería y la matemática se cruzan para dar forma a una enorme cantidad de cosas sobre las que está hecha buena parte de la tecnología moderna: desde la codificación, compresión y transmisión de datos hasta buena parte del análisis criptográfico moderno. Siguió trabajando toda su vida en la estructura y posibilidades de lo que llamaba máquinas pensantes, y buena parte del análisis está en la base de los algoritmos contemporáneos de análisis y generación de lenguaje natural. Dice mucho sobre nosotros que alguien tan central a nuestra época sea casi un desconocido fuera del ámbito de quienes se dedican a esto.
A mind at play: How Claude Shannon invented the information age, Soni, J. y Goodman, R. Simon and Shuster (2017)
Esos bits son un poco distintos de los bits de Shannon. Un baudio, o bit por segundo, acá quiere decir que el canal es capaz de cambiar de estado una vez por segundo. 1 megabit por segundo quiere decir que el canal puede cambiar de estado un millón de veces por segundo. Algunos puristas llaman binits a la medida de capacidad física y bits a la medida de información de Shannon, pero la ultima vez que uno pidió en Mercado Libre un disco de ocho terabinits para su compu lo lincharon entre varios, y desde entonces el nombre cayo un poco en desuso.
Me encantó el comentario totalmente Felperiano sobre Steven Seagal
Cursé Teoría de la Información en el CAECE, hara unos 42 o 43 años... Creo que nunca había vuelto sobre el tema.